
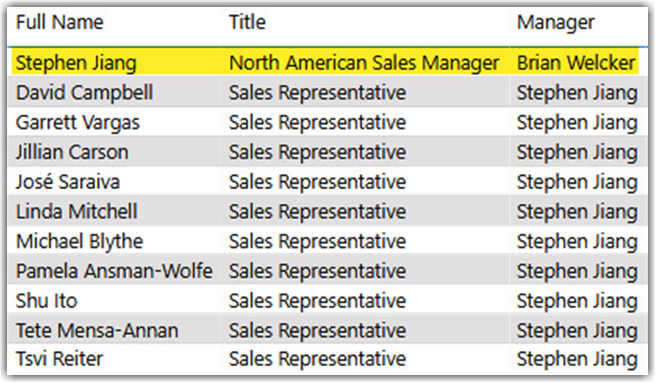
Slowly changing dimension (SCD) is a data warehousing concept coined by the amazing Ralph Kimball. The SCD concept deals with moving a specific set of data from one state to another. Imagine a human resources (HR) system having an Employee table. As the following image shows, Stephen Jiang is a Sales Manager having ten sales representatives in his team:
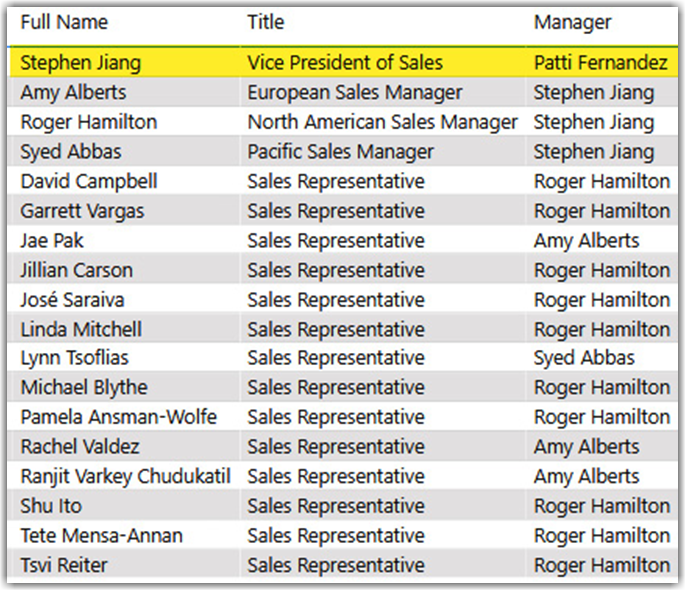
Today, Stephen Jiang got his promotion to the Vice President of Sales role, so his team has grown in size from 10 to 17. Stephen is the same person, but his role is now changed, as shown in the following image:
Another example is when a customer’s address changes in a sales system. Again, the customer is the same, but their address is now different. From a data warehousing standpoint, we have different options to deal with the data depending on the business requirements, leading us to different types of SDCs. It is crucial to note that the data changes in the transactional source systems (in our examples, the HR system or a sales system). We move and transform the data from the transactional systems via ETL (Extract, Transform, and Load) processes and land it in a data warehouse, where the SCD concept kicks in. SCD is about how changes in the source systems reflect the data in the data warehouse. These kinds of changes in the source system do not happen very often hence the term slowly changing. Many SCD types have been developed over the years, which is out of the scope of this post, but for your reference, we cover the first three types as follows.
SCD type zero (SCD 0) #
With this type of SCD, we ignore all changes in a dimension. So, when a person’s residential address changes in the source system (an HR system, in our example), we do not change the landing dimension in our data warehouse. In other words, we ignore the changes within the data source. SCD 0 is also referred to as fixed dimensions.
SCD type 1 (SCD 1) #
With an SCD 1 type, we overwrite the old data with the new. An excellent example of an SCD 1 type is when the business does not need the customer’s old address and only needs to keep the customer’s current address.
SCD type 2 (SCD 2) #
With this type of SCD, we keep the history of data changes in the data warehouse when the business needs to keep the old and current data. In an SCD 2 scenario, we need to maintain the historical data, so we insert a new row of data into the data warehouse whenever a transactional system changes. A change in the transactional system is one of the following:
- Insertion: When a new row inserted into the table
- Updating: When an existing row of data is updated with new data
- Deletion: When a row of data is removed from the table
Let’s continue with our previous example of a Human Resource system and the Employee table. Inserting a new row of data into the Employee dimension in the data warehouse for every change within the source system causes data duplications in the Employee dimensions in the data warehouse. Therefore we cannot use the EmployeeKey column as the primary key of the dimension. Hence, we need to introduce a new set of columns to guarantee the uniqueness of every row of the data, as follows:
- A new key column that guarantees rows’ uniqueness in the Employee dimension. This new key column is simply an index representing each row of data stored in a data warehouse dimension. The new key is a so-called surrogate key. While the Surrogate Key guarantees each row in the dimension is unique, we still need to maintain the source system’s primary key. By definition, the source system’s primary keys are now called business keys or alternate keys in the data warehousing world.
- A Start Date and an End Date column represent the timeframe during which a row of data is in its current state.
- Another column shows the status of each row of data.
SCD 2 is the most common type of SCD. After we create the required columns
Let’s revisit our scenario when Stephen Jiang was promoted from Sales Manager to Vice President of Sales. The following screenshot shows the data in the Employee dimensions in the data warehouse before Stephen got the promotion:

The EmployeeKey column is the Surrogate Key of the dimension, and the EmployeeBusinessKey column is the Business Key (the primary key of the customer in the source system); the Start Date column shows the date Stephen Jiang started his job as North American Sales Manager, the End Date column has been left blank (null), and the Status column shows Current. Now, let’s have a look at the data after Stephen gets the promotion, which is illustrated in the following screenshot:

As the above image shows, Stephan Jiang started his new role as Vice President of Sales on 13/10/2012 and finished his job as North American Sales Manager on 12/10/2012. So, the data is transformed while moving from the source system into the data warehouse. As you see, handling SCDs is one of the most crucial tasks in the ETL processes.
Let’s see what SCD 2 means when it comes to data modeling in Power BI. The first question is: Can we implement SCD 2 directly in Power BI Desktop without having a data warehouse? To answer this question, we must remember that we always prepare the data before loading it into the model. On the other hand, we create a semantic layer when building a data model in Power BI. In a previous post, I explained the different components of a BI solution, including the ETL and the semantic layer. But I repeat it here. In a Power BI solution, we take care of the ETL processes using Power Query, and the data model is the semantic layer. The semantic layer, by definition, is a view of the source data (usually a data warehouse), optimised for reporting and analytical purposes. The semantic layer is not to replace the data warehouse and is not another version of the data warehouse either. So the answer is that we cannot implement the SCD 2 functionality purely in Power BI. We need to either have a data warehouse keeping the historical data, or the transactional system has a mechanism to support maintaining the historical data, such as a temporal mechanism. A temporal mechanism is a feature that some relational database management systems such as SQL Server offer to provide information about the data kept in a table at any time instead of keeping the current data only. To learn more about temporal tables in SQL Server, check this out.
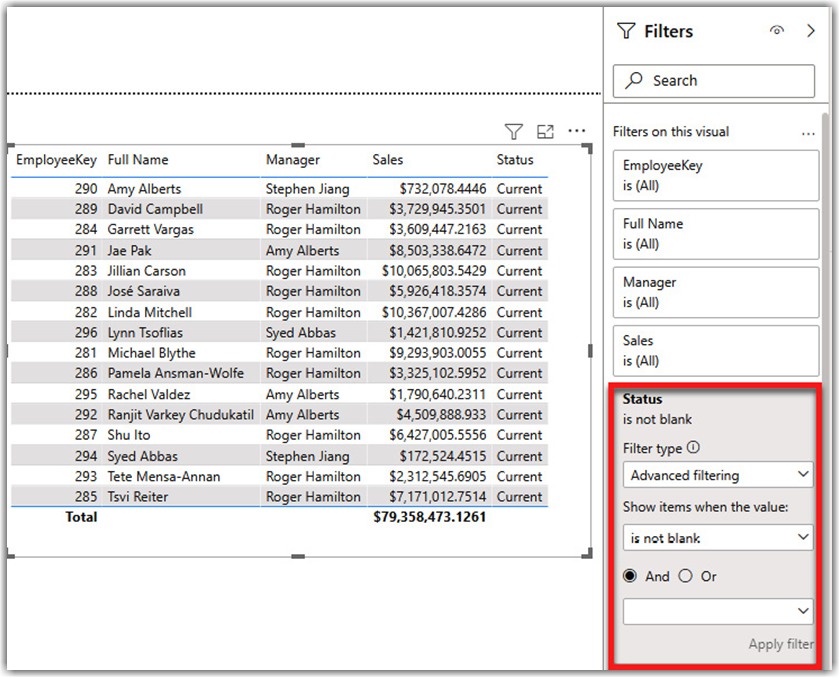
After we load the data into the data model in Power BI Desktop, we have all current and historical data in the dimension tables. Therefore, we have to be careful when dealing with SCDs. For instance, the following screenshot shows reseller sales for employees:
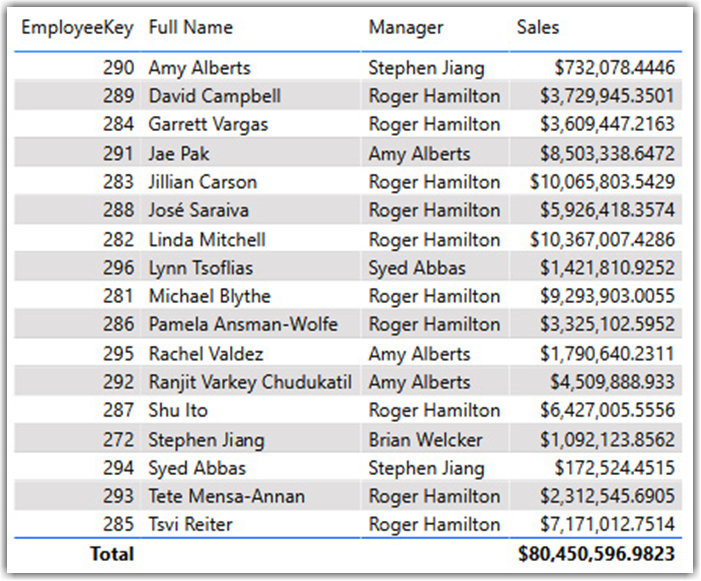
At a first glance, the numbers seem to be correct. Well, they may be right; they may be wrong. It depends on what the business expects to see on a report. Look at Image 4, which shows Stephen’s changes. Stephen had some sales values when he was a North American Sales Manager (EmployeeKey 272). But after his promotion (EmployeeKey 277), he is not selling anymore. We did not consider SCD when we created the preceding table, which means we consider Stephen’s sales values (EmployeeKey 272). But is this what the business requires? Does the business expect to see all employees’ sales without considering their status? For more clarity, let’s add the Status column to the table.
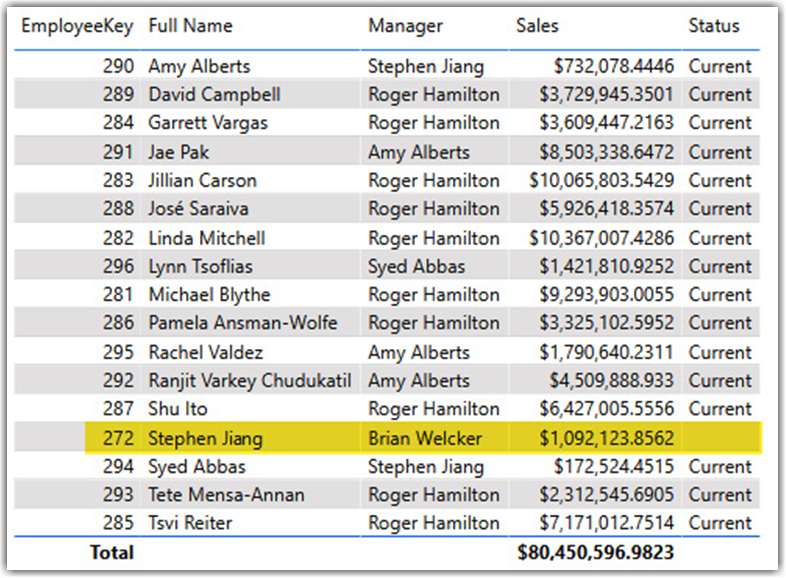
What if the business needs to only show sales values only for employees when their status is Current? In that case, we would have to factor the SCD into the equation and filter out Stephen’s sales values. Depending on the business requirements, we might need to add the Status column as a filter in the visualizations, while in other cases, we might need to modify the measures by adding the Start Date, End Date, and Status columns to filter the results. The following screenshot shows the results when we use visual filters to take out Stephen’s sales:
Dealing with SCDs is not always as simple as this. Sometimes, we need to make some changes to our data model.
So, do all the above mean we cannot implement any types of SCDs in Power BI? The answer, as always, is “it depends.” In some scenarios, we can implement a solution similar to the SCD 1 functionality, which I explain in another blog post. But we are out of luck in implementing the SCD 2 functionality purely in Power BI.
Have you used SCDs in Power BI, I am curious to know about the challenges you faced. So please share you thoughts in the comments section below.
Discover more from BI Insight
Subscribe to get the latest posts sent to your email.
You can implement SCD2 in Power Query as long as you have snapshot data. Snapshot data is like a pull from the source system on a regular basis. You can write a function in M code that compares changes in records for each period and adds start date, end date, and current for each record after removing records that hadn’t changed. Although it’s not the ideal solution, it is possible.
Hi Bernard,
Thanks for your comment and for sharing your thoughts.
You’re right that if we have regular snapshot data, we can technically use Power Query to implement something that resembles SCD Type 2 by comparing changes and assigning effective dates.
However, I think it’s important to look at the bigger picture and question whether Power Query is the right tool to handle this kind of logic.
Also, the semantic model in Power BI is just that. It is a semantic layer, meant for reporting and analytics, not for implementing data warehousing patterns or as a replacement for data warehouses. Trying to manage SCD2 purely at this layer bends the architecture in ways that are hard to maintain and scale.
If we look this in the context of Microsoft Fabreic, again, if we already have access to Lakehouses or Warehouses to implementing SCD logic in those layers, which is much more appropriate.
So yes, SCD2 logic can be done in Power Query in certain cases. But should it be?
Thanks again for engaging with the content!